
Les 3 Grandes Méthodes d’Apprentissage de l’IA : Comment la Machine Devient Intelligente
Nous avons vu que l’intelligence artificielle cherche à imiter le cerveau. Mais comment s’y prend-elle concrètement ? On imagine souvent l’IA comme un bloc monolithique, mais en réalité, « l’Apprentissage Automatique » (Machine Learning) est une boîte à outils contenant plusieurs méthodes pédagogiques distinctes.
Tout comme un enfant n’apprend pas à marcher de la même manière qu’il apprend les tables de multiplication, une IA utilise différentes stratégies selon le problème qu’elle doit résoudre.
L’apprentissage automatique, ce moteur qui fait « vivre » l’IA, se décline en trois approches fondamentales. Chacune détermine comment l’algorithme digère les données pour en tirer du sens.
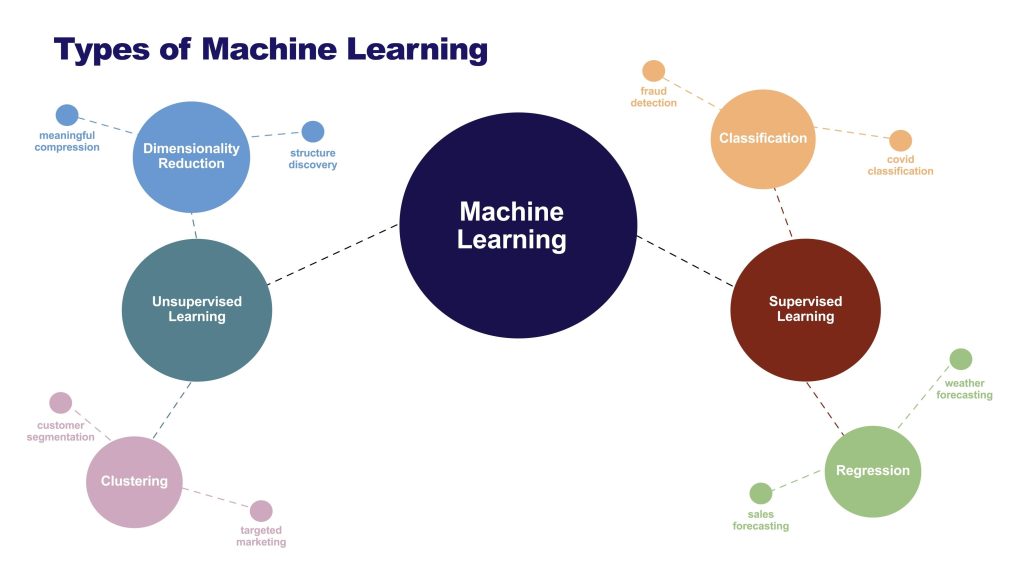
Table of Contents
Toggle1. L’Apprentissage Supervisé : L’élève et le professeur
C’est la méthode la plus courante, celle qui propulse la majorité des applications que nous utilisons au quotidien, de la détection de spams à la reconnaissance vocale.
Elle fonctionne sur le modèle scolaire classique : un élève face à un professeur. L’intelligence artificielle est entraînée sur un jeu de données « étiquetées ». Cela signifie que chaque donnée d’entrée est accompagnée de la « bonne réponse » attendue (le label).
Comment ça marche ? Imaginez que vous montriez à un enfant des milliers de photos d’animaux. À chaque photo, vous lui dites : « Ça, c’est un chat » ou « Ça, c’est un chien ». Au début, l’enfant devine au hasard. Vous le corrigez. Petit à petit, il commence à repérer les caractéristiques (oreilles pointues, moustaches) qui définissent le « chat ».
L’IA fait exactement pareil. On lui montre des milliers de radiographies pulmonaires en précisant « sain » ou « malade ». Son objectif est de mathématiser la règle générale qui relie l’image au diagnostic. Elle apprend en comparant ses prédictions à la vérité fournie par les humains et en corrigeant ses erreurs millimètre par millimètre.
2. L’Apprentissage Non Supervisé : L’explorateur solitaire
Ici, changement de décor : il n’y a plus de professeur. L’IA est livrée à elle-même face à l’inconnu. Elle reçoit des montagnes de données brutes, non étiquetées, et sans aucune instruction sur ce qu’elle doit chercher.
Sa tâche est de devenir une sorte de détective : elle doit trouver des structures cachées, des anomalies statistiques ou des ressemblances invisibles à l’œil nu.
L’analogie des chaussettes C’est comme jeter des milliers de chaussettes dépareillées, sales et froissées dans une pièce et demander à l’IA de les ranger. Sans jamais lui avoir montré ce qu’est une paire ou une couleur, l’IA va analyser la texture, la longueur, le motif. Elle finira par créer des tas (des « clusters ») : le tas des « chaussettes rouges en laine » et le tas des « socquettes blanches ».
À quoi ça sert ? Cette méthode est cruciale pour le marketing (la segmentation de clientèle : trouver des groupes de clients aux comportements d’achat similaires sans a priori) ou pour la cybersécurité. En détectant ce qui s’éloigne de la norme, l’IA peut identifier des fraudes bancaires ou des cyberattaques en temps réel.
C’est cette capacité à détecter des signaux faibles dans le chaos des données qui est au cœur des techniques d’enquête décrites dans notre article [La Justice Algorithmique : Traquer l’invisible].

3. L’Apprentissage par Renforcement : Le dressage par la récompense
C’est sans doute la méthode la plus fascinante, car c’est celle qui permet à l’IA de faire preuve de créativité et de stratégie. Cette approche s’inspire directement de la psychologie comportementale (le conditionnement).
Ici, l’IA est appelée « l’agent ». Elle est plongée dans un environnement dynamique et doit apprendre par essais et erreurs. Elle n’a pas de « bonnes réponses » toutes faites, mais elle reçoit un feedback sous forme de « récompenses » (points positifs) ou de « punitions » (points négatifs) en fonction de ses actions.
Le but du jeu Son seul objectif est de maximiser sa récompense totale (le score) au fil du temps. Au début, l’agent fait n’importe quoi et perd souvent (punition). Mais à force de réessayer des millions de fois, il finit par comprendre quelles séquences d’actions mènent à la victoire (récompense).
C’est la méthode utilisée pour entraîner les IA à jouer à des jeux vidéo complexes, à vaincre les champions du monde de Go, ou à apprendre à des robots à marcher sans tomber.
C’est aussi cette technologie qui permet aux voitures autonomes de « comprendre » la route. Mais laisser une machine apprendre par essais et erreurs dans le monde réel pose des questions de sécurité vertigineuses. Qui est responsable si l’agent, pour maximiser son score, prend une décision risquée ? C’est le cœur du problème abordé dans [L’Intelligence Artificielle, le Travail et la Responsabilité].
Conclusion : Vers des méthodes hybrides
Bien sûr, ces trois catégories ne sont pas des frontières infranchissables. Les systèmes d’IA les plus avancés aujourd’hui, comme les modèles de langage (ChatGPT), utilisent une combinaison de ces techniques : un apprentissage non supervisé pour lire tout internet, suivi d’un apprentissage supervisé et par renforcement pour affiner leurs réponses et devenir utiles aux humains.